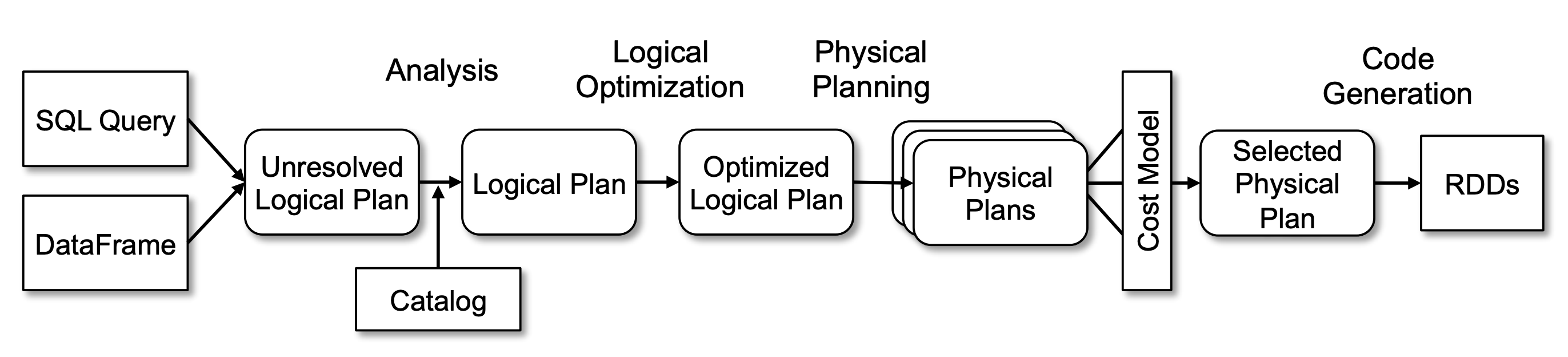
书接上回,如何不修改 Spark 源码对 Spark Catalyst 引擎扩展 中介绍了如何自定义 Spark Catalyst 引擎,这次再来一个实践中的场景:在数据量很大的接入任务中,对表进行分区,此分区对用户隐藏,当用户根据指定的时间字段过滤查询的时候,自动加上分区过滤条件。
概述 这里优化的一个前提是用户在配置接入任务过程中,需要标记一个时间字段,用于分区存储优化,然后再接入过程中对此字段进行解析,保存到分区 year=yyyy/month=MM/day=dd 中。
比如时间字段是 ctime,用户 SQL 是 where ctime > '2022-11-30 12:00:00' 进过我们的优化规则之后,会变成 where ctime > '2022-11-30 12:00:00' AND concat(year, month, day) >= '20221130';甚至用户可以使用 substring 函数,比如 where substring(ctime, 1, 10) >= '2021-12-12' 也可以优化为 where substring(ctime, 1, 10) >= '2021-12-12' AND concat(year, month, day) >= '20211212',当然这里其实不是修改 SQL,而是修改的逻辑执行计划。
一个测试 SQL:select * from test where dt > '2022-11-30 00:00:00'
未经优化的逻辑计划:
1 2 3 Project [id#0, dt#1, year#2, month#3, day#4] +- Filter (isnotnull(dt#1) AND (dt#1 > 2022-11-30 00:00:00)) +- FileScan parquet xx.test[id#0,dt#1,year#2,month#3,day#4] Batched: true, DataFilters: [isnotnull(dt#1), (dt#1 > 2022-11-30 00:00:00)], Format: Parquet, Location: CatalogFileIndex(1 paths)[hdfs://xx.db/test], PartitionFilters: [], PushedFilters: [IsNotNull(dt), GreaterThan(dt,2022-11-30 00:00:00)], ReadSchema: struct<id:string,dt:string>
优化后:PartitionFilters 部分正是我们添加的分区过滤条件
1 2 3 Project [id#0, dt#1, year#2, month#3, day#4] +- Filter (isnotnull(dt#1) AND (dt#1 > 2022-11-30 00:00:00)) +- FileScan parquet xx.test[id#0,dt#1,year#2,month#3,day#4] Batched: true, DataFilters: [isnotnull(dt#1), (dt#1 > 2022-11-30 00:00:00)], Format: Parquet, Location: InMemoryFileIndex(2 paths)[hdfs://xx.db/test/year=2022/month=12/day..., PartitionFilters: [(concat(year#2, month#3, day#4) >= 20221130)], PushedFilters: [IsNotNull(dt), GreaterThan(dt,2022-11-30 00:00:00)], ReadSchema: struct<id:string,dt:string>